| Version 33 (modified by , 14 years ago) (diff) |
|---|
Parallel-DT
- Short Name: Parallel-DT
- SVN: https://svn-batch.grid.pub.ro/svn/PP2009/proiecte/Parallel-DT
- Team members: Eremia Bogdan, Andrei Minca, Alexandru Sorici
- Project Description: Classification is an important data mining problem. One of the most popular algorithms used for classification purposes are decision trees (DT). Since datasets that are used in data mining problems are usually very large, computationally efficient and scalable algorithms are highly desirable. Thus, the project's goal is to parallelize the decision tree inference process. A shared memory programming model using OpenMP is being considered for this task.
- Project Presentation: https://ncit-cluster.grid.pub.ro/trac/PP2009/attachment/wiki/Parallel-DT/Parallel-DT.ppt
- Project Implementation Details: Details
Serial DT process
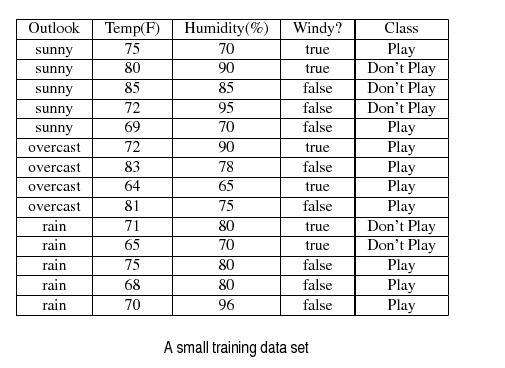
Most of the existing induction-based algorithms, also C4.5 that is analysed on this topic, use Hunt's method as the basic algorithm. Here is a recursive description of Hunt's method for constructing a decision tree from a set T of trainning cases with classes denoted {C1, C2, C3, ..., Ck} :
- Case 1 T contains cases all belonging to a single class Cj. The decision tree for T is a leaf identifying class Cj.
- Case 2 T contains cases that belong to a mixture of classes. A test is chosen, based on a single attribute, that has one or more mutually exclusie outcomes {O1, O2, O3, ..., On}. note that in many implementation n is chosen to be 2 and this leads to a binary decision tree. T is partitioned into subsets T1, T2, ..., Tn, where Ti contains all the cases in T that have outcome Oi of the chosen test. The decision tree for T consists of a decision node identifying the test, and one branch for each possible outcome. The same tree building machinery is applied recursively to each subset of training cases.
- Case 3 T containes no cases. the decision tree for T is a leaf, but the class to be asociated with the leaf must be determined from information other than T. For example, C4.5 chosses this to be the most frequent class at the parent of this node.



Parallel approaches
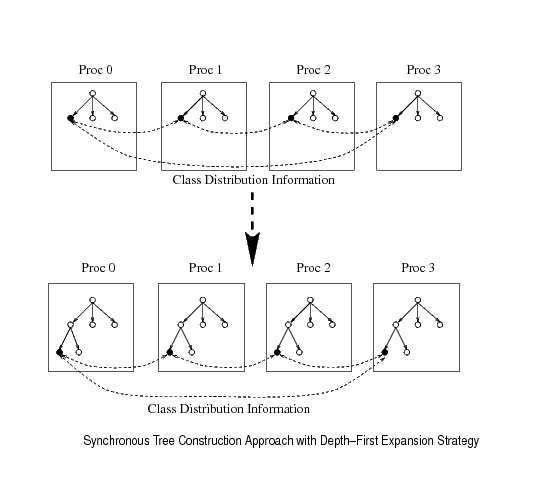
- Syncronous Tree Construction - Depth First Expansion Strategy - the one that we implemented
In this approach, all processors construct a decision tree syncronously by sending and receiving class distribution information of local data. Major steps for the approach:
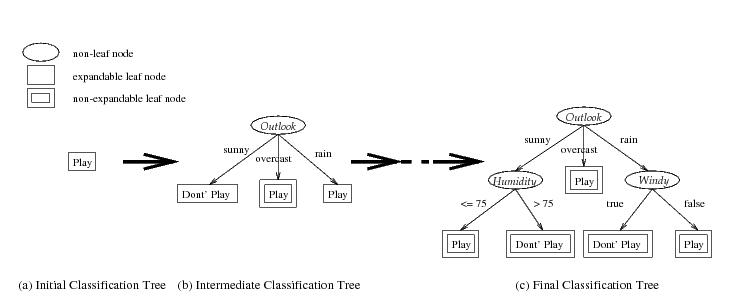
- select a node to expand according to a decision tree expansion strategy (eg Depth-First or Breadth-First), and call that node as the current node. At the beginning, root node is selected as the current node
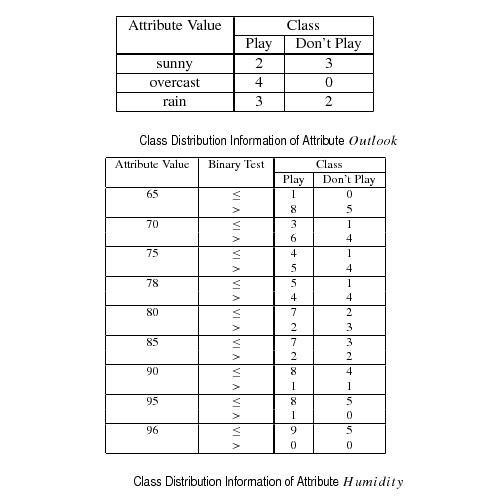
- for each data attribute, collect class distribution information of the local data at the current node
- exchange the local class distribuition information using global reduction among processors
- simultaneously compute the entropy gains of each attribute at each processor and select the best attribute for child node expansion
- depending on the branching factor of the tree desired, create child nodes for the same number of partitions of attributes values, and split training cases accordingly

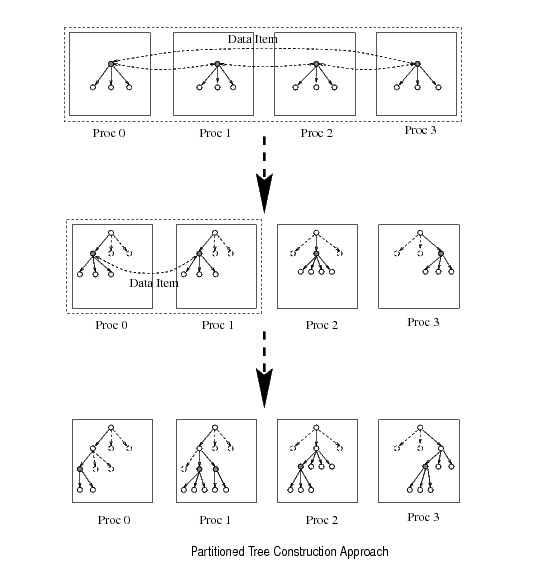
- Partitioned Tree Construction
In this approach, whenever feasible, deifferent processors work on different parts of the classification tree.

Project activity
Steps:
- 12 Nov
- Project status: still researching :) - ToDo: chose the best aproach for the serial code that we have
Attachments (6)
-
T.JPG (40.3 KB) - added by 14 years ago.
a small training data set
-
F.JPG (23.3 KB) - added by 14 years ago.
steps in creating the decision tree
-
Outlook&Humidity.jpg (44.2 KB) - added by 14 years ago.
Outlook and Humidity attributes
-
SyncronusTreeConstruction-DepthFirstExpansionStrategy.jpg (44.0 KB) - added by 14 years ago.
syncronous treeconstruction
-
PartitionedTreeConstruction.jpg (56.9 KB) - added by 14 years ago.
partitioned tree construction
-
Parallel-DT.ppt (226.0 KB) - added by 14 years ago.
Project Presentation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip