| Version 6 (modified by , 14 years ago) (diff) |
|---|
Performance Analysis
We describe in this section the infrastructure we used for testing, the parameters we considered as relevant when running the tests and the results we obtained.
Testing Infrastructure
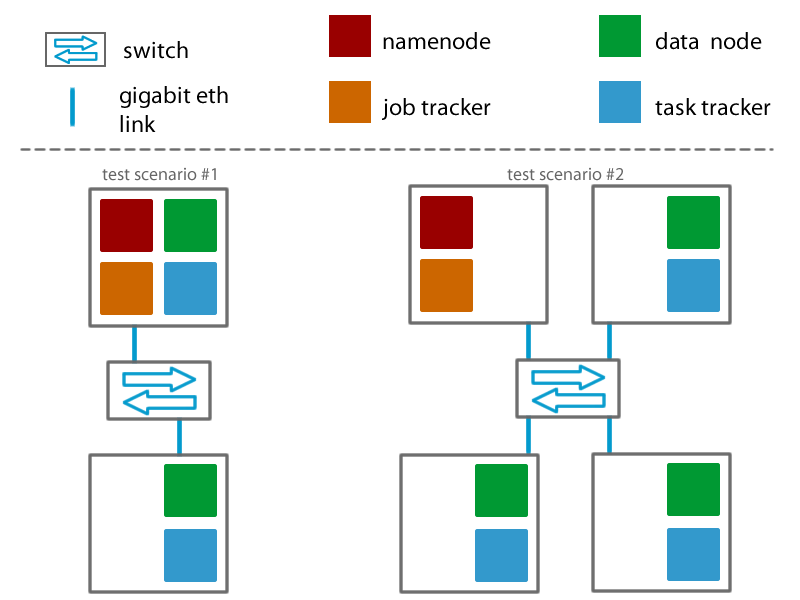
As the main idea of a distributed system is to use commodity hardware, we have used a maximum of four computers from ED202, running Ubuntu 8.04, Hadoop 0.20.1, Pig 0.5.0. They were interconnected using a Gigabit switch, so as to obtain the maximum from infrastructure's point of view.
The first test scenario uses two nodes. For the Hadoop Framework, one of them is master, having in the same time master attributions (namenode - keeps the structure of the file system, jobTracker - keeps track of the jobs' execution), taskTracker - keeps track of the tasks...
TODO continue Claudiu for the whole testing infrastructure
Parameters
Hadoop
The MapReduce? Framework from Hadoop offers a very large number of parameters to be configured for running a job. One can set the number of maps, which is usually driven by the total size of the inputs and the right level of parallelism seems to be around 10-100 maps per node. Because task setup takes a while, one should make sure it's worth it, consequently the maps should run at least a minute. Hadoop dinamically configures this parameter. Also, one can set the number of reduce tasks, a thing we should pay more attention to.
MPI
Comparison
- High performance and scalability
- Portability
- Productivity is not a principal objective for MPI!!
Attachments (7)
- throughput_2.png (6.1 KB) - added by 14 years ago.
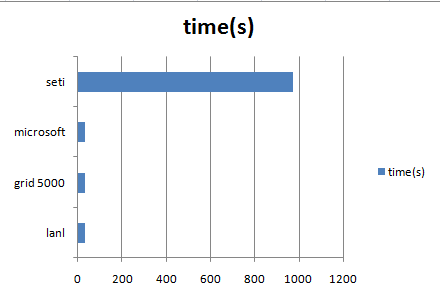
- time_chart.png (5.4 KB) - added by 14 years ago.
- time_char_1.png (5.0 KB) - added by 14 years ago.
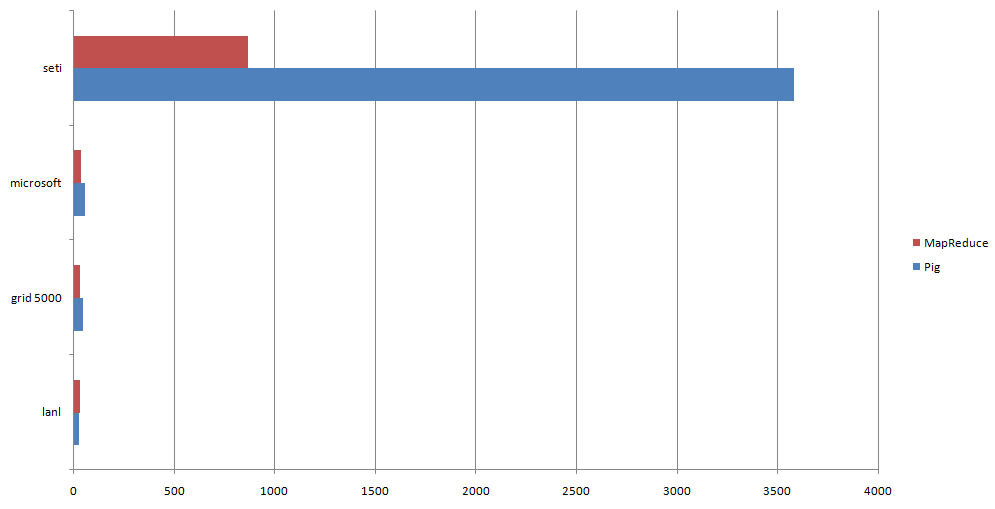
- mr_vs_pig.png (6.9 KB) - added by 14 years ago.
-
testing.png (19.1 KB) - added by 14 years ago.
Testing infrastructure
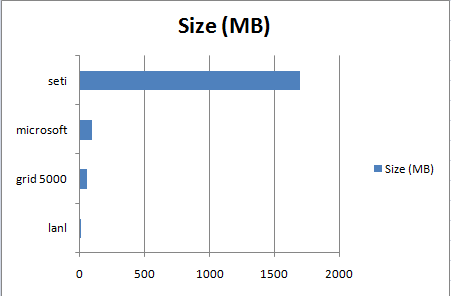
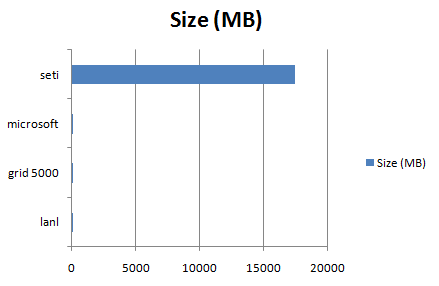
- size_chart.png (5.1 KB) - added by 14 years ago.
-
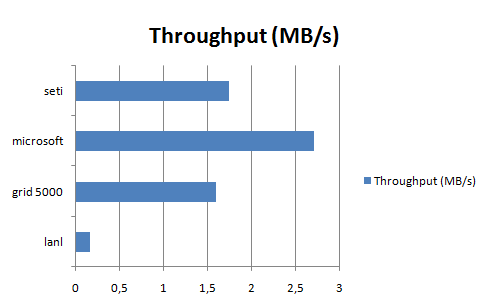
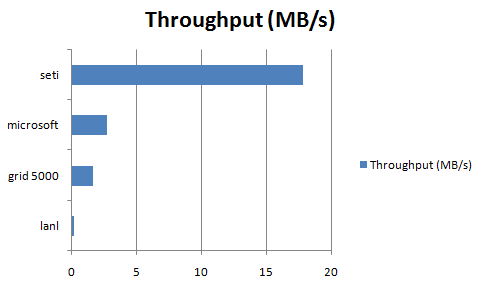
throughput.png (5.9 KB) - added by 14 years ago.
throughput chart
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip