| Version 10 (modified by , 14 years ago) (diff) |
|---|
Performance Analysis
We describe in this section the infrastructure we used for testing, the parameters we considered as relevant when running the tests and the results we obtained.
Testing Infrastructure
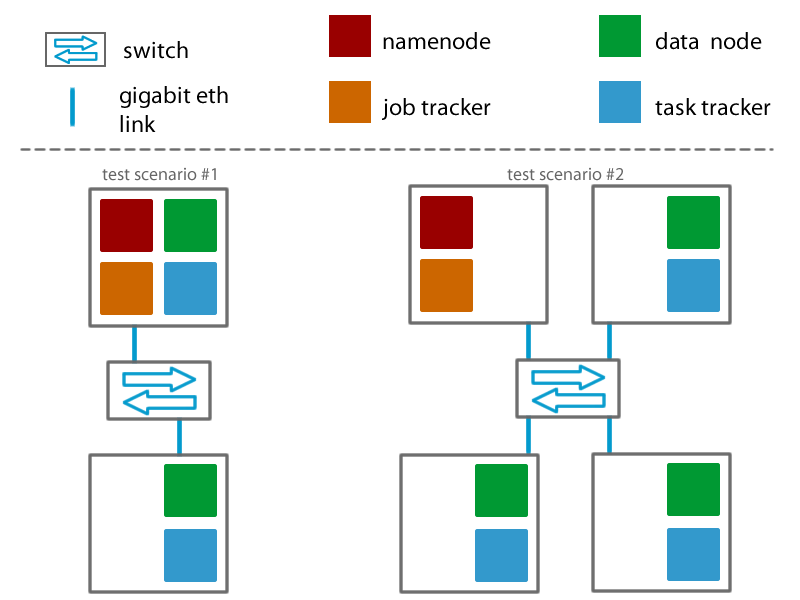
As the main idea of a distributed system is to use commodity hardware, we have used a maximum of four computers from ED202, running Ubuntu 8.04, Hadoop 0.20.1, Pig 0.5.0. They were interconnected using a Gigabit switch, so as to obtain the maximum from infrastructure's point of view.
The first test scenario uses two nodes. For the Hadoop Framework, one of them is master, having in the same time master attributions (namenode - keeps the structure of the file system, jobTracker - keeps track of the jobs' execution), taskTracker - keeps track of the tasks...
TODO continue Claudiu for the whole testing infrastructure
Parameters
Hadoop
The MapReduce? Framework from Hadoop offers a very large number of parameters to be configured for running a job.
One can set the number of maps, which is usually driven by the total size of the inputs and the right level of parallelism seems to be around 10-100 maps per node. Because task setup takes a while, one should make sure it's worth it, consequently the maps should run at least a minute. Hadoop dinamically configures this parameter.
Also, one can set the number of reduce tasks, a thing we payed more attention to. The right number of reduces seems to be 0.95 or 1.75 multiplied by (<no. of nodes> * mapred.tasktracker.reduce.tasks.maximum). With 0.95 all of the reduces can launch immediately and start transfering map outputs as the maps finish. With 1.75 the faster nodes will finish their first round of reduces and launch a second wave of reduces doing a much better job of load balancing. Moreover, increasing the number of reduces increases the framework overhead, but increases load balancing and lowers the cost of failures. Running jobs as they were resulted in just one reducer, which obviously had no load balancing at all. Having these in mind, we set the number of reducers at 5 as appropriate for out testing infrastructure mentioned above.
Another interesting parameter is the replication factor in HDFS, which should be lower than the number of DataNodes? so as not to use too much space, but sufficient to allow parallelism while placing jobs where data is. We set this to 2 both when we had 2 and 4 nodes in the cluster.
There are no parameters to configure for Pig. Although this gives no headackes, it isn't a performance friendly solution.
MPI
A major bottleneck in MPI is the comunication, so out main preoccupation was to pay attention to message sizes, not to large but also not too small and not too frequent. Also overlapping IO and computation is of high importance. Moreover, MPI2 has some interesting features, like dynamic creation of processes and parallel I/O.
Results
We evaluated the frameworks from a high performance and scalability point of view.
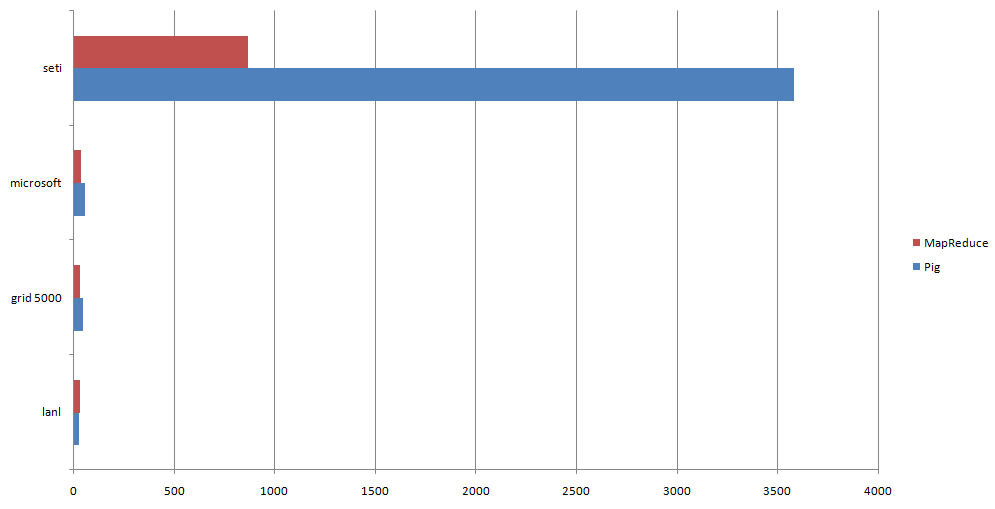
In the 2-cluster node, MapReduce?'s tunning gave results and it performed much better than Pig. 
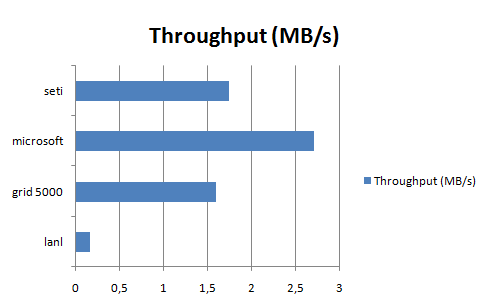
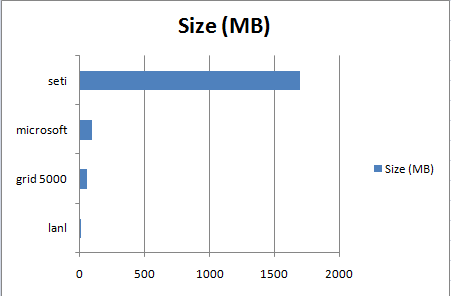
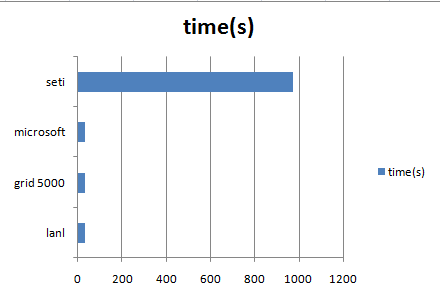
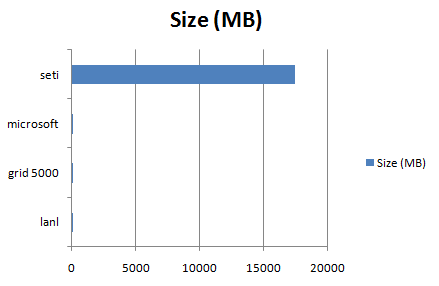
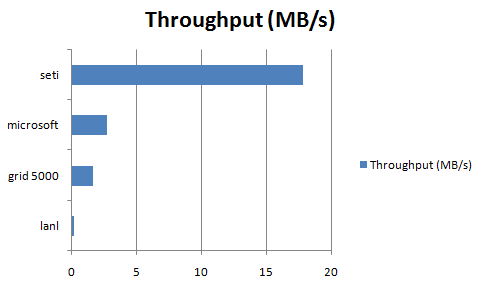
The framework is indeed suitable for large data processing, as shown in the charts below. Increasing the replication factor would have probably increased the throughput for the seti dataset 

 .
.
Here are some detailed tests results with the number of tasks, maps and reduces.
When testing the 4 nodes cluster, after the first job (failureCause application on seti dataset, which performed 12s in MapReduce? instead of 14s in MapReduce? on the 2 nodes cluster) one of the nodes froze and Hadoop proves it's fault tolerance by succeeding in running the tests, without however giving relevant results. But from the first test's output, we can conclude that there was some scalability there.
We didn't test the applications for MPI as the jobs in Hadoop took a really long time and we considered them more challenging. However, in out applications we assumed that the data was somehow present on all slaves, which in practice is not true. Consequently, we think MPI needs and underlying distributed file system, like NFS, to do things properly.
From a portability point of view, Hadoop passes the test. We cannot say the same about MPI, which is highly dependend on the runtime system underneath. For example, the proper asynchronous message sending level deppends on the buffers used by the RTS. Also some MPI implementations may offer things others lack.
Its interesting to discuss productivity
Attachments (7)
- throughput_2.png (6.1 KB) - added by 14 years ago.
- time_chart.png (5.4 KB) - added by 14 years ago.
- time_char_1.png (5.0 KB) - added by 14 years ago.
- mr_vs_pig.png (6.9 KB) - added by 14 years ago.
-
testing.png (19.1 KB) - added by 14 years ago.
Testing infrastructure
- size_chart.png (5.1 KB) - added by 14 years ago.
-
throughput.png (5.9 KB) - added by 14 years ago.
throughput chart
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip