| Version 2 (modified by , 14 years ago) (diff) |
|---|
Conclusions
From a portability point of view, Hadoop passes the test. We cannot say the same about MPI, which is highly dependend on the runtime system underneath. For example, the proper asynchronous message sending level deppends on the buffers used by the RTS. Also some MPI implementations may offer things others lack.
It's interesting to discuss productivity. From an engineer's point of view, who knows what happens underneath, MapReduce? is probably the best choice. Developing in Pig is in a way similar to sql, so leads to a great productivity for those not so familiar with how things are done, but is still not very stable and the weird error messages may lead to a greater development time than MapReduce?. Also, its differences from sql, for instance grouping is not done in the same statement with applying group functions, may get people used to sql quite often into trouble. Working in MPI at a low level may increase performance, but we think the development time it's not worth. Developers must be aware of synchronization and overlapping IO and computation, which is not trivial.
Our first choice would be MapReduce?, or at least Hadoop. The whole framework managing files, fault tolerance, migrating jobs and also offering logs is a productivity friendly environment.
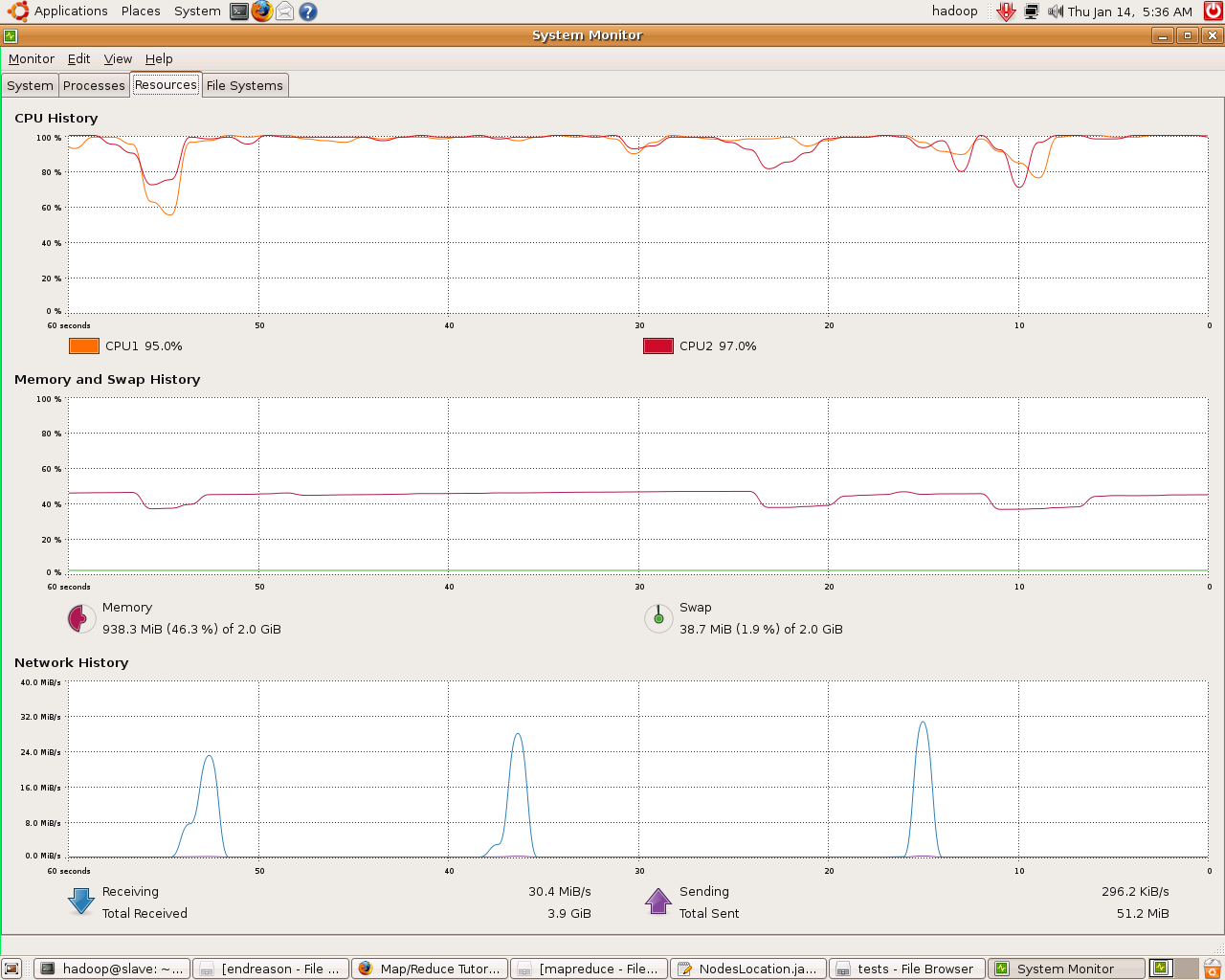
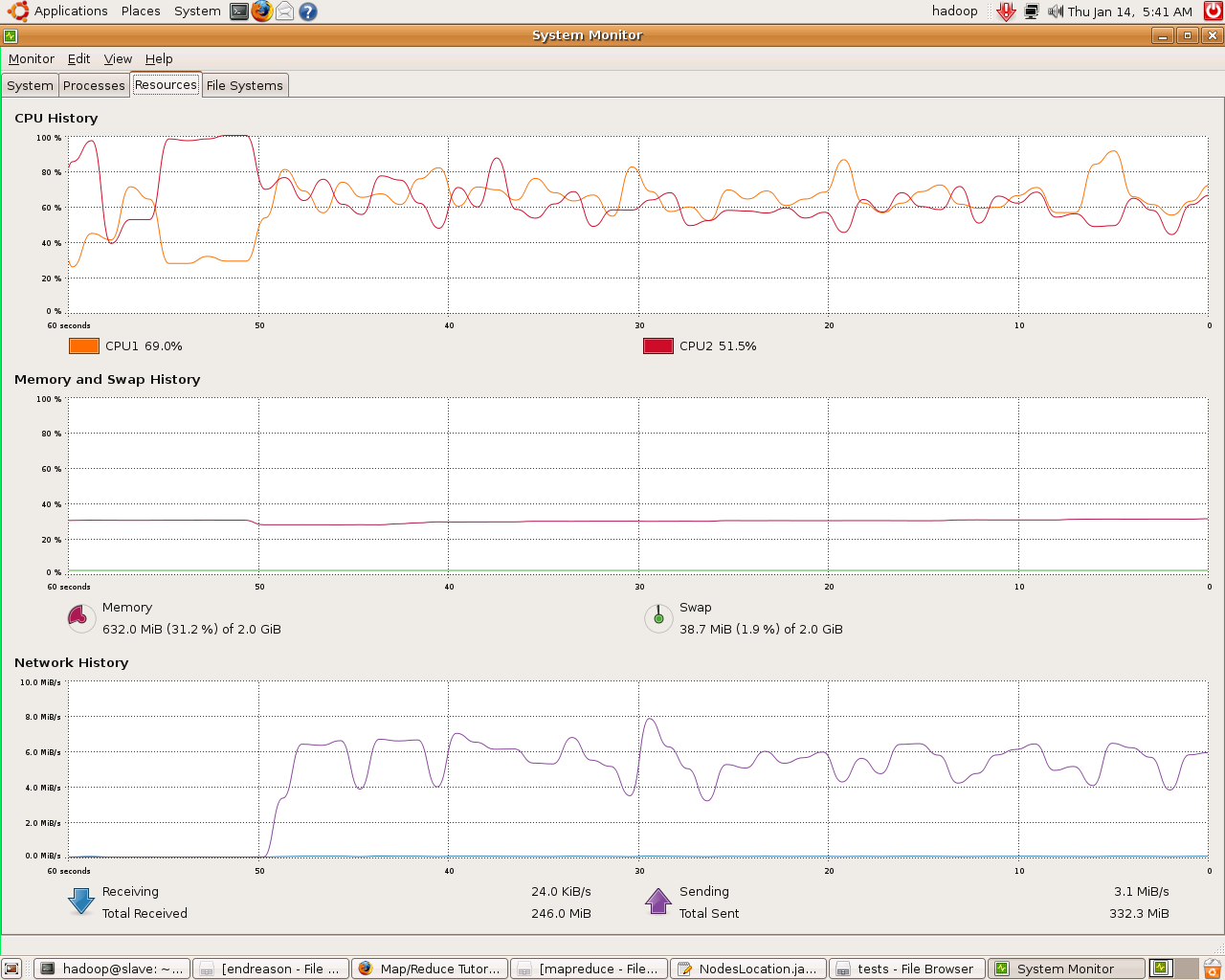
Finally, we present you some images of slaves@work in ED202:
map task
reduce task
Attachments (2)
- slave_monitor_pig-seti.png (92.3 KB) - added by 14 years ago.
- slave_red_pig-seti.png (111.7 KB) - added by 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip