| Version 7 (modified by , 14 years ago) (diff) |
|---|
Applications
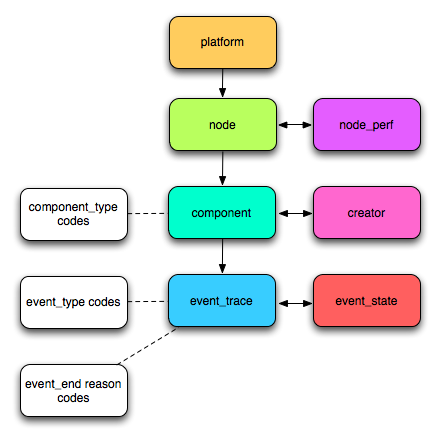
We decided to do several application in the realm of statistics on large amount of data, keeping in mind to choose them as different as possible so as to make the comparison more relevant. As a result, we chose some real world data, available online at INRIA Failure Trace Archive, having as an advantage the fact that data is structured and we could test the applications on various input sizes, from tens on MB to tens of GB. This data archive presents facts about job failures and the tales of interest for out applications are event_trace (a trace of events that failed), node (identifies nodes on which the jobs ran), component (describes component codes), event_trace.event_end_reason code. A full description of these tables is available at the link mentioned earlier.
Below there is a short description of each application:
- Which one of the fault reasons is the most frequent? This application uses the event_trace table, looking at event_end_reason column
- Which is the medium duration for events? This application uses the event_trace table, looking at event_start_time and event_end_time columns
- Which component is the most frequent as a fault cause? This application uses the event_trace table, using the component_id column and also the table component table, looking at component_type column
- Having a classification for job duration as short, medium and long, find out the most frequent (>1000) causes of failures for each of these categories. It uses event_trace table, looking at event_start_time and event_end_time columns and also event_trace.event_end_reason code table.
- For each category from event_trace.event_end_reason code ranges, which of event_trace.event_end_reason code definitions is the most frequent?
- Number of failures for each geographical location. This application uses the event_trace table, more precisely the columns platform_id and node_id so as to identify the nodes that failed, and then maps them with the location by using the table node, having among others the columns node.platform_id and node.node_id.
MapReduce
Making design choices for MapReduce? is an intricate task. On the one hand, there are many decisions to be made, such as to have or not to have a Combiner (cuts down the amount of data transferred from the Mapper to the Reducer), a Partitioner (partitions the output of mappers per reducer), or even a CompressionCodec? (compresses the intermediate outputs from mappers to reducers) or a Comparator to do a secondary sort before the reduce phase. On the other hand, complex combinations in specifying these extra features may lead to a too long development time, which is not worth it. TODO Claudiu for his apps
Pig
On the contrary to MapReduce?, writing code in PigLatin? is as straight forward as it can be TODO Claudiu for his apps
MPI
TODO Claudiu for his apps
Attachments (1)
- schema_fta.png (41.9 KB) - added by 14 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip