| Version 12 (modified by , 14 years ago) (diff) |
|---|
HadoopJUnitRunner: Hadoop Distributed JUnit Runner
![]()
- Team members: Matei Gruber - gruber.matei, Andreea Lucau - lucau.andreea
- The purpose of this project is to evaluate and implement a way of running in a distributed environment JUnit tests. We've chosen Hadoop as a distributed framework.
- Hadoop official site
- JUnit official site
![]()
Project Timeline
- 18 October - Setting up the Hadoop environment, run simple examples
- 2 November - Run a simple JUnit test, with no dependencies
- 29 November - Implement a resource server - used for sending classes to the HDFS
- 15 December - Run JUnit tests with dependencies and add simple results reporting
- 3 January - Add extended error reporting: the entire stack trace
Motivation
The purpose of this project is to run a large number of tests in a distributed environment in order to get faster results and to take advantage of the available distributed infrastructures available nowadays. We chose to use Hadoop, an open source framework that comes with its own distributed filesystem and a MapReduce? implementation. We used the pseudo-distributed configuration, that creates clusters locally, on the host machine. As testing tool, we used JUnit, a popular testing framework. We aim to offer the end used developer the same experience when running JUnit tests on a normal host machine as when running it with Hadoop, but having the advantages of running in a distributed environment: higher speed.
Project Architecture
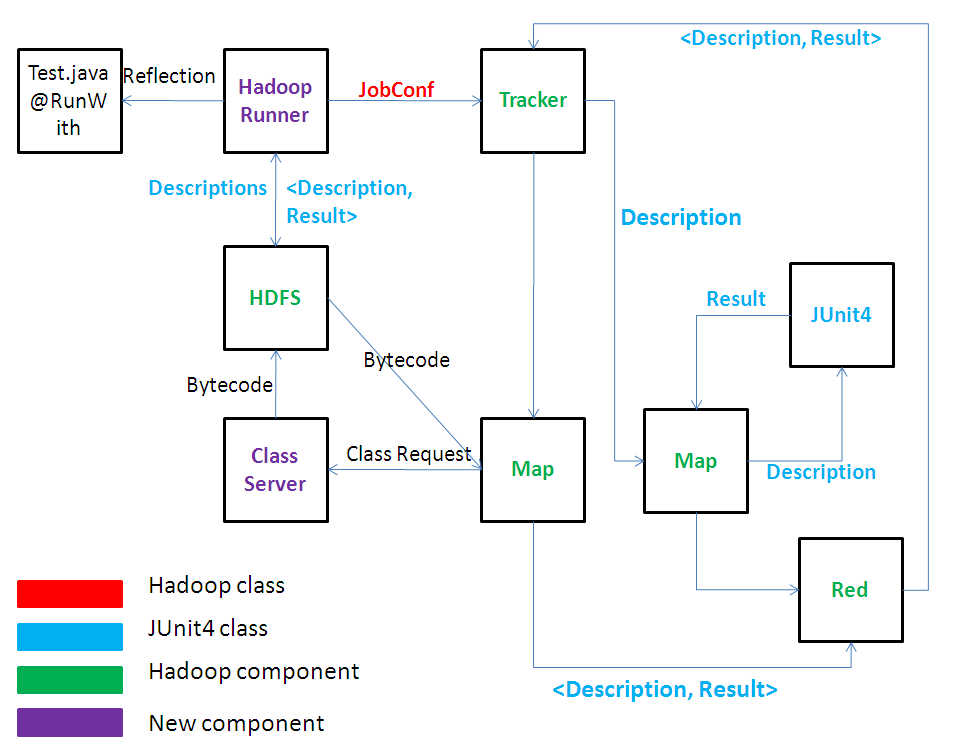
 In order to explain the architecture of the project, lets follow a normal execution. A user adnotates a JUnit test class with "@RunWith?(HadoopRunner?.class)". At runtime, the JUnit will then use our own test runner. Our runner checks the test class for the descriptions of the tests we want to run, writes then into a file and send this file to the Hadoop core. In the Map phase, we read the description of the tests and then try to run the tests. If the tests requires some additional classes, the HadoopRunner? will send a request to a resource server for that class. The resource server will load the class into the HDFS and the HadoopRunner? will launch a classic JUnit runner to run the test on the cluster. In the Reduce phase, we gather the results of the tests. We send back a serialized version of the running result and then deserialize it and report the results.
In order to explain the architecture of the project, lets follow a normal execution. A user adnotates a JUnit test class with "@RunWith?(HadoopRunner?.class)". At runtime, the JUnit will then use our own test runner. Our runner checks the test class for the descriptions of the tests we want to run, writes then into a file and send this file to the Hadoop core. In the Map phase, we read the description of the tests and then try to run the tests. If the tests requires some additional classes, the HadoopRunner? will send a request to a resource server for that class. The resource server will load the class into the HDFS and the HadoopRunner? will launch a classic JUnit runner to run the test on the cluster. In the Reduce phase, we gather the results of the tests. We send back a serialized version of the running result and then deserialize it and report the results.
Development Problems
During the development phase of the project we encountered several problems. We describe them bellow and also the solution we have chosen.
Sending tests to clusters
We had to design a protocol for sending the tests we want to run into the clusters, running them and finally, gathering the results. Do accomplish this, we decided to get the Description of each test we want to run (Description is a JUnit class, containing information about a single test), serialize it and send it into the cluster. Also, we would put on the HDFS a jar containing the JUnit test classes. In the Map phase we would deserialize the class Description, run the test and finally, in the Reduce phase, we would serialize the result and send back to the centralized management console a pair <Description Result>.
Loading resources into the cluster
At runtime, a test may require custom user defined classes. It would be impossible for a developer to know in advanced all the classed it may need to run the tests in all situation. So we needed a way of getting the test required classes into the cluster. Hadoop has its own ClassLoader? that searches classes in the Hadoop Java environment, but this wasn't enough for us. So using the Hadoop API, we could get a hold of the situations when the Hadoop class loader needed classes that weren't already loaded into the HDFS and send a request for the class to a class server (a new component) and copy the bytecode of the class on the HDFS.
Reporting results
After running the tests, in the reduce phase, we needed a way of sending the results to the centralized management console. The problem was that the classic JUnit runner returner a Result class, that wasn't serializable. So we transformed this class into a byte array, encoded into a Base64 format and send the result in this format and upon receiving it, we would decode the bytes and recreate the object.
Attachments (5)
-
HadoopRunnerArchitecture.PNG (41.4 KB) - added by 14 years ago.
This document describer the Hadoop JUnit runner architecture
-
Presentation.pdf (193.4 KB) - added by 14 years ago.
Project Presentation
-
logo-junit-org.gif (3.4 KB) - added by 14 years ago.
JUnit Logo
-
hadoop_logo.png (34.1 KB) - added by 14 years ago.
Hadoop Logo
-
logo-junit-org.2.gif (3.4 KB) - added by 14 years ago.
JUnit Logo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip