| Version 41 (modified by , 14 years ago) (diff) |
|---|
GAIIA
- The team: Mihai Istin - mihai.istin , Andreea Visan - andreea.visan
Abstract
Task scheduling is one of the most important management aspects in a distributed system because this component should achieve two main goals: on the one hand efficient use of available resources and on the other hand high performance in solving tasks. Because of the fact that the scheduling problem is an NP-Complete problem, a near-optimal algorithm is a desired solution. A third goal is the fact that the algorithm should provide the results very fast. This project's aim is to develop a parallel solution for a near-optimal algorithm for dependent task scheduling in distributed systems.
Technologies and Languages
- C/C++
- MPI
- OPENMP
Project Activity (main steps)
- the serial solution - OPENMP tunning - MPI tunning - experimental tests, conclusions
Details
The Problem
The input:
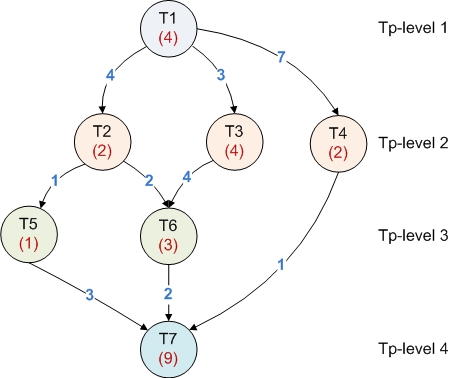
- The graph of tasks that have to be scheduled. Each task is represented as a node while the dependencies between tasks are represented as edges. Each tasks (node) has associated a computational cost and each dependency (edge) has an communication costs.

- The processor topology graph which is also described as a DAG. Each node represent a processor (and the weight represents the speed) while each edge represents the communication cost between processors.
The output:
- The schedule with contains the mapping of tasks on processors and the order of tasks to be executed on the same processor.
The goal:
- load balancing
- minimum makespan
- minimum idle times
The proposed algorithm
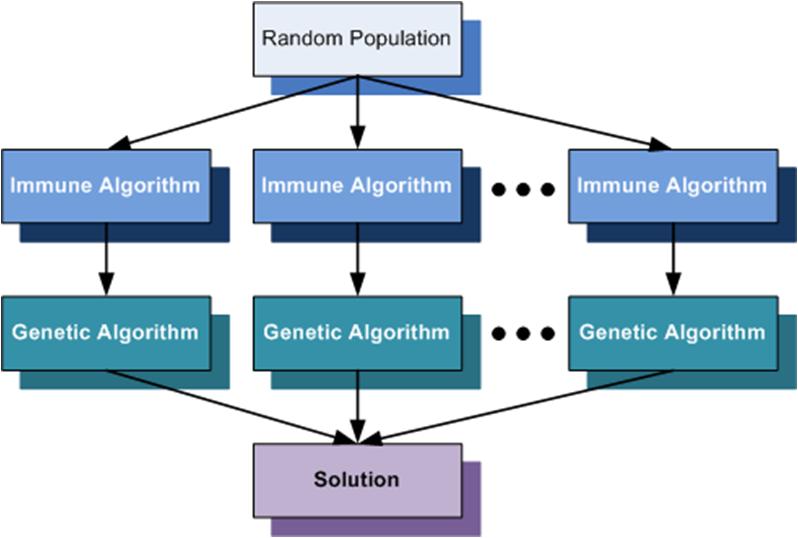
Our solution is based on a hybrid evolutionary algorithm with combines the benefits of genetic and immune algorithms algorithms in order to provide efficient solutions. It is known that the convergence time of genetic algorithms is highly influenced by the average fitness of the initial population. So if we could find a way to provide a population with an good average fitness at the initialization phase of the genetic algorithm, the algorithm will converge faster.
Immune algorithms are also bio-inspired algorithms that are based on the human immune system model. They evolve a population of antibodies in order to fit better the antigens that are threatening the immune system.
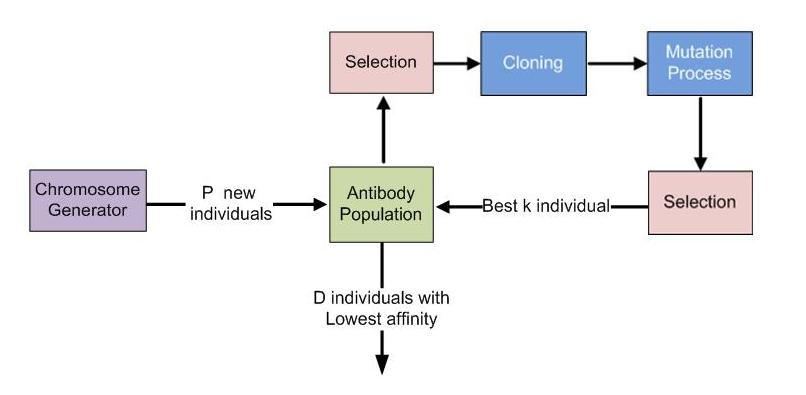
As a computational model, immune algorithms can be designed to evolve a population of chromosomes representing the antibodies in order to have a good fitness. The implementation of such algorithms is based on the clonal selection principle which model the response of an immune system to an intruder. Basically, the current population of antibodies is evaluated and the best individuals (individuals with the best fitness) are selected for the maturation process. During this process, for each selected individual will be made a number of clones proportionally with its fitness. Then each clone will suffer multiple mutations. The number of mutations will be inverse proportionally with its fitness. Then, the clones are evaluated, and the best are selected in order to survive to the next generation. The antibodies with the lowest fitness will be removed from the current population.
The main advantage of immune algorithms is that they are capable of evolving a population with a good average fitness after only several iteration. On the other hand these algorithms have also a drawback: as a consequence of the fact that the mutation rate varies inverse proportionally with the fitness, the best individuals will be similar. But if we are aware of this drawback we can control the diversity of the evolved population by using only a few generations and by using reinsertion.
The Immune Algorithms
In the following figure is presented the general model for the immune algorithms. The number of clones is computed using the following formula

- uses genetic algorithms
- chromosome representation:

- uses the topological level and the inverse topological level of a node
- introduces the notion of floating nodes:

- single point crossover
- 3 types of mutation:
- partial-gene mutation - swap-gene mutation - topological hyper-mutation
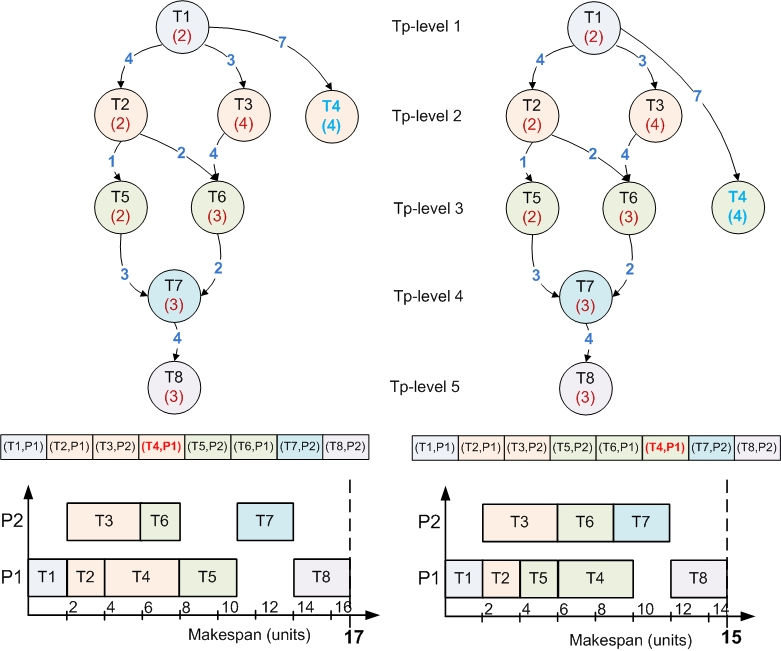
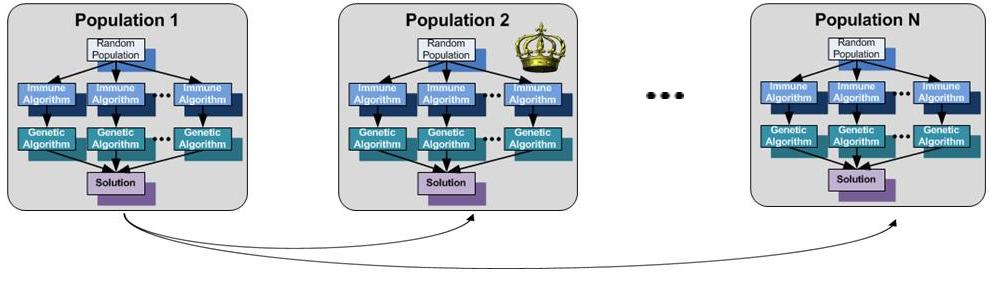
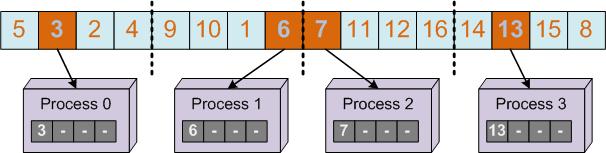
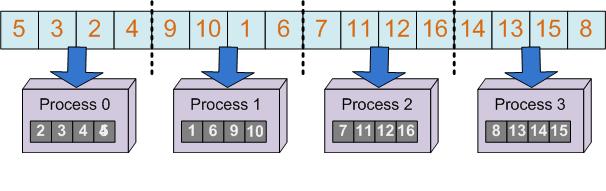
The Parallel Solution
- The Parallel Execution Model
 Execution model")
- The Distributed Execution Model
 Execution model")
Compiling, Running, Profiling
- the OpenMP version
g++ -g -fopenmp -o scheduler main.cpp ...
qsub -q ibm-quad.q -pe openmpi 1 -v OMP_NUM_THREADS=4 script.h
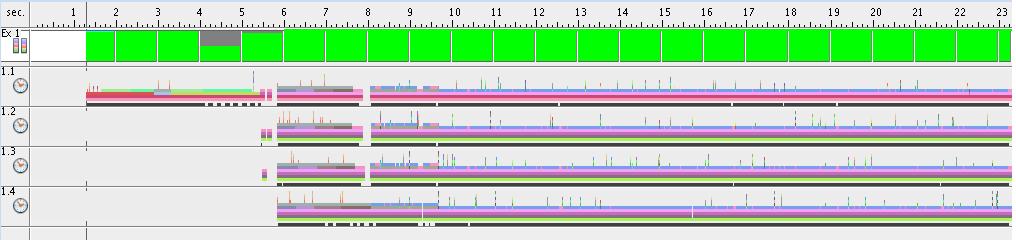
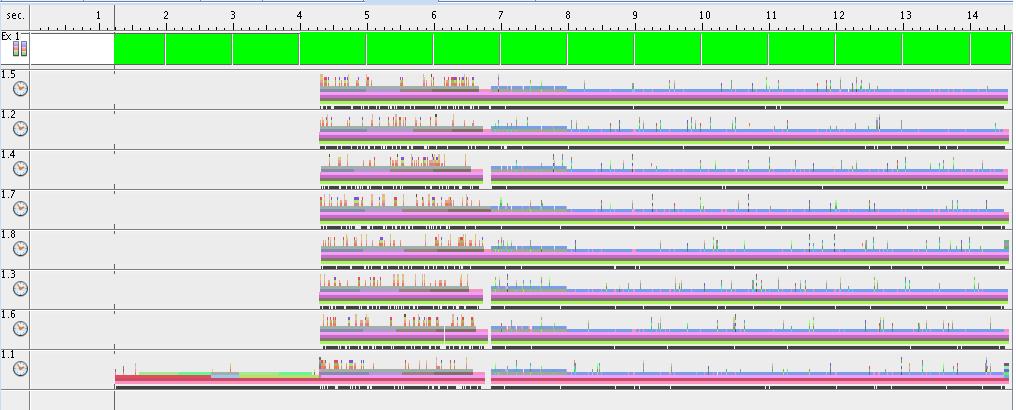
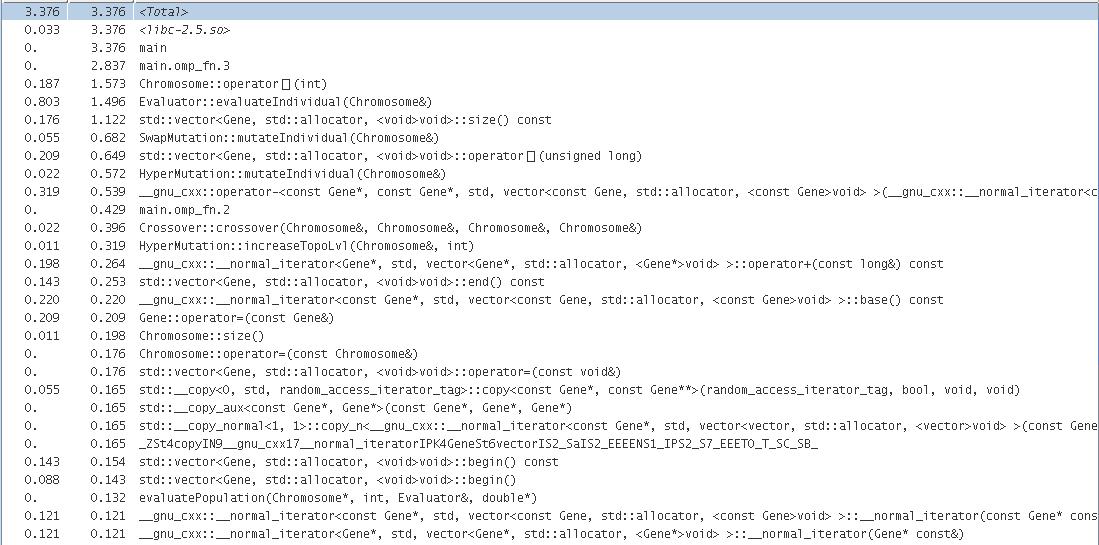
Experimental results
Sun Studio Performance Analyzer results:
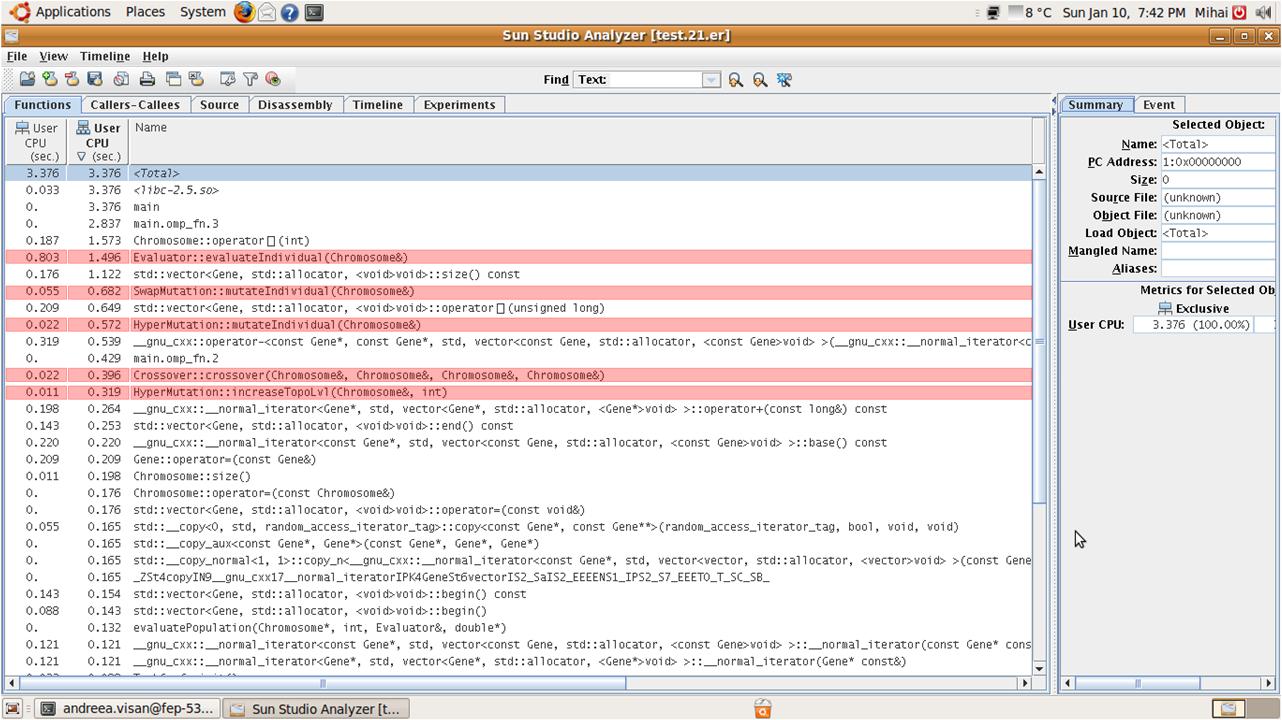
- function overview

- OMP version - 1 thread

- OMP version - 2 thread

- OMP version - 4 thread

- OMP version - 8 thread

- Evolution - Summary
")
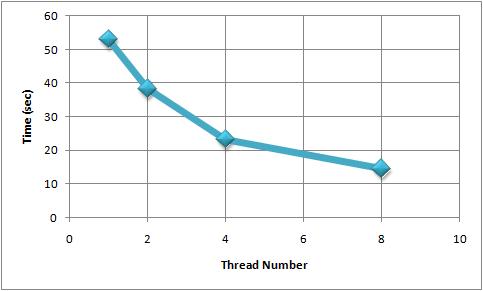
- Execution time for each thread (8 threads situation)

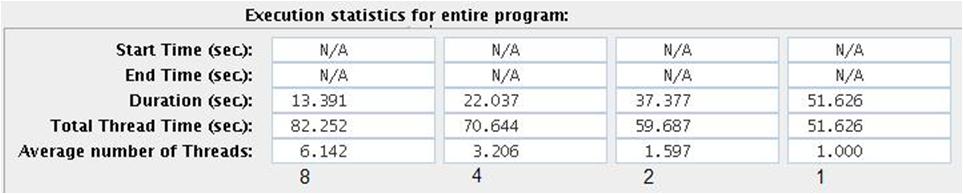
- Execution statistics for the entire program for 1,2,4 and 8 threads

Attachments (23)
-
chromosome.jpg (18.2 KB) - added by 14 years ago.
The chromosome's representation
-
DAG.jpg (52.1 KB) - added by 14 years ago.
The DAG of tasks
-
floating_nodes.jpg (170.8 KB) - added by 14 years ago.
Example of floating nodes
- 1.jpg (29.2 KB) - added by 14 years ago.
-
2.jpg (37.1 KB) - added by 14 years ago.
Execution - 2 threads
-
4.jpg (50.1 KB) - added by 14 years ago.
Execution - 4 threads
-
8.jpg (76.4 KB) - added by 14 years ago.
Execution - 8 threads
-
overview.jpg (124.1 KB) - added by 14 years ago.
Sun Studio Performance Analyzer - function overview
-
ia.jpg (22.6 KB) - added by 14 years ago.
The Immune Algorithm
-
execp.jpg (37.0 KB) - added by 14 years ago.
(Parallel) Execution model
-
execd.jpg (41.3 KB) - added by 14 years ago.
(Distributed) Execution model
- grafic2.jpg (170.1 KB) - added by 14 years ago.
-
grafic1.jpg (16.6 KB) - added by 14 years ago.
Evolution (thread)
- runtime.jpg (21.1 KB) - added by 14 years ago.
- tab.jpg (13.1 KB) - added by 14 years ago.
- tab2.jpg (29.3 KB) - added by 14 years ago.
- form1.jpg (5.8 KB) - added by 14 years ago.
- form2.jpg (6.4 KB) - added by 14 years ago.
- form3.jpg (9.6 KB) - added by 14 years ago.
- tour.jpg (19.7 KB) - added by 14 years ago.
- sort1.jpg (21.4 KB) - added by 14 years ago.
- sort2.jpg (16.6 KB) - added by 14 years ago.
- multi.png (25.4 KB) - added by 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
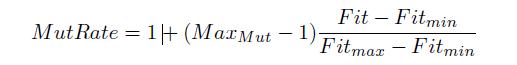{kind=link}
{kind=link}
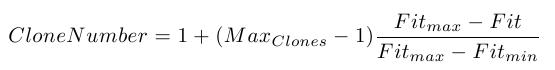{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip